
Why Every AI Data Company Sounds Identical & Two That Don't

I spent a few days reading the homepages of 20+ AI and data companies back-to-back. Semantic layers, data integration platforms, observability tools, cloud warehouses. All with the same dozen words, rearranged.
The word “agentic” (which barely existed in vendor marketing eighteen months ago) appears on seven of them. Cube calls itself “THE Agentic Analytics Platform.” Acceldata calls itself an “Agentic Data Management Platform.” These companies do fundamentally different things. But have the same adjective.
AI-generated or lazy copywriting isn’t the issue though.
It’s a problem with positioning. When every company sounds the same, it means none of them have made a real choice about who they serve and why.
Snowflake ($3.4B in product revenue) and Databricks ($2.4B run rate) can afford this. They have billions in brand equity, sales armies, and analyst relationships doing the work their homepages don’t. Vague messaging is a luxury when you’re already the default name a CIO thinks of.
This piece is about everyone else. The Series A observability startup. The seed-stage BI tool. The open-source project building a commercial layer. For them, sounding like Snowflake isn’t “great-artists-steal”, it’s simply invisible. Invisible is fatal without a $500M sales team to compensate.
The Echo Chamber, Quantified
I audited eight companies in detail - dbt, Fivetran, Databricks, Snowflake, Monte Carlo, Bigeye, Acceldata, and Matillion and tracked their homepage language against a set of common “power words.”
The repetition is far from subtle. Snowflake uses "trusted, scalable AI Data Cloud." dbt promises to "deliver trusted data." Acceldata ensures "trusted, reliable, and AI-ready data at scale." Bigeye's entire repositioning hinges on "AI Trust Platform."

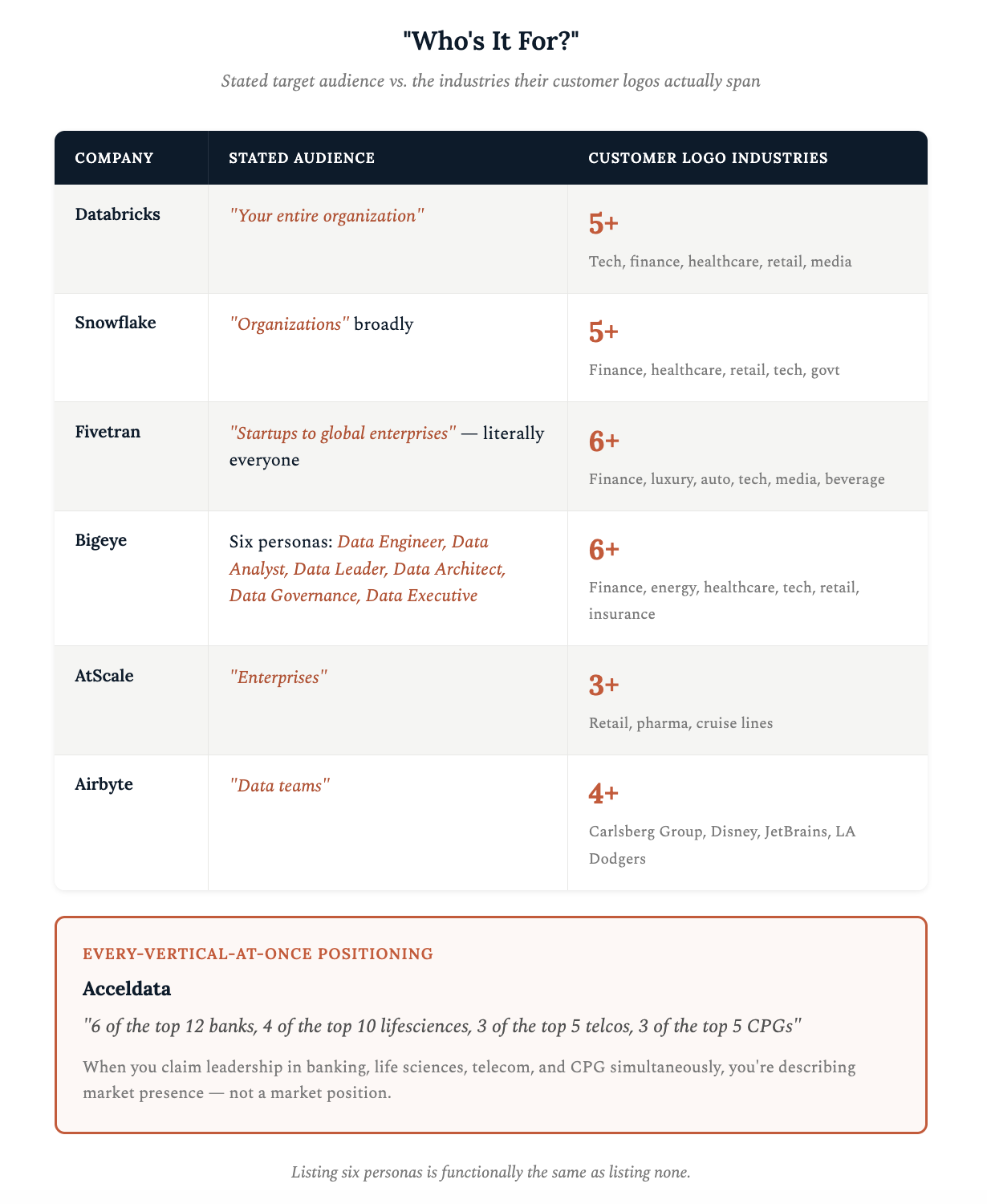
Buyer language is where the sameness gets absurd. Databricks addresses “your entire organization.” Snowflake speaks to “organizations” broadly. Fivetran targets “startups to global enterprises” (that’s literally everyone). Bigeye lists six persona titles: Data Engineer, Data Analyst, Data Leader, Data Architect, Data Governance, Data Executive. Listing six personas is functionally the same as listing none.
Customer pages aren’t better. Every audited company displays logo bars across at least five unrelated industries with no segmentation logic. AtScale shows retail next to pharma next to cruise lines. Airbyte mixes Carlsberg Group with Disney, JetBrains, and the LA Dodgers.
G2 reviews show a gap between what vendors market and what the actual users say. The vendor language is so far from the buyer language that the two barely ever overlap.

Another pattern is the humanized AI copilot. Matillion now leads its homepage with “Meet Maia: Your data engineering buddy.” We saw shared adjectives and now shared narrative is on the rise. Name the AI, give it a personality, call it a buddy, make it the hero. Same playbook, new cover.
Three Reasons Everyone Sounds the Same
Category adolescence creates mimicry. In young markets, the best-funded company sets the vocabulary and everyone copies it.
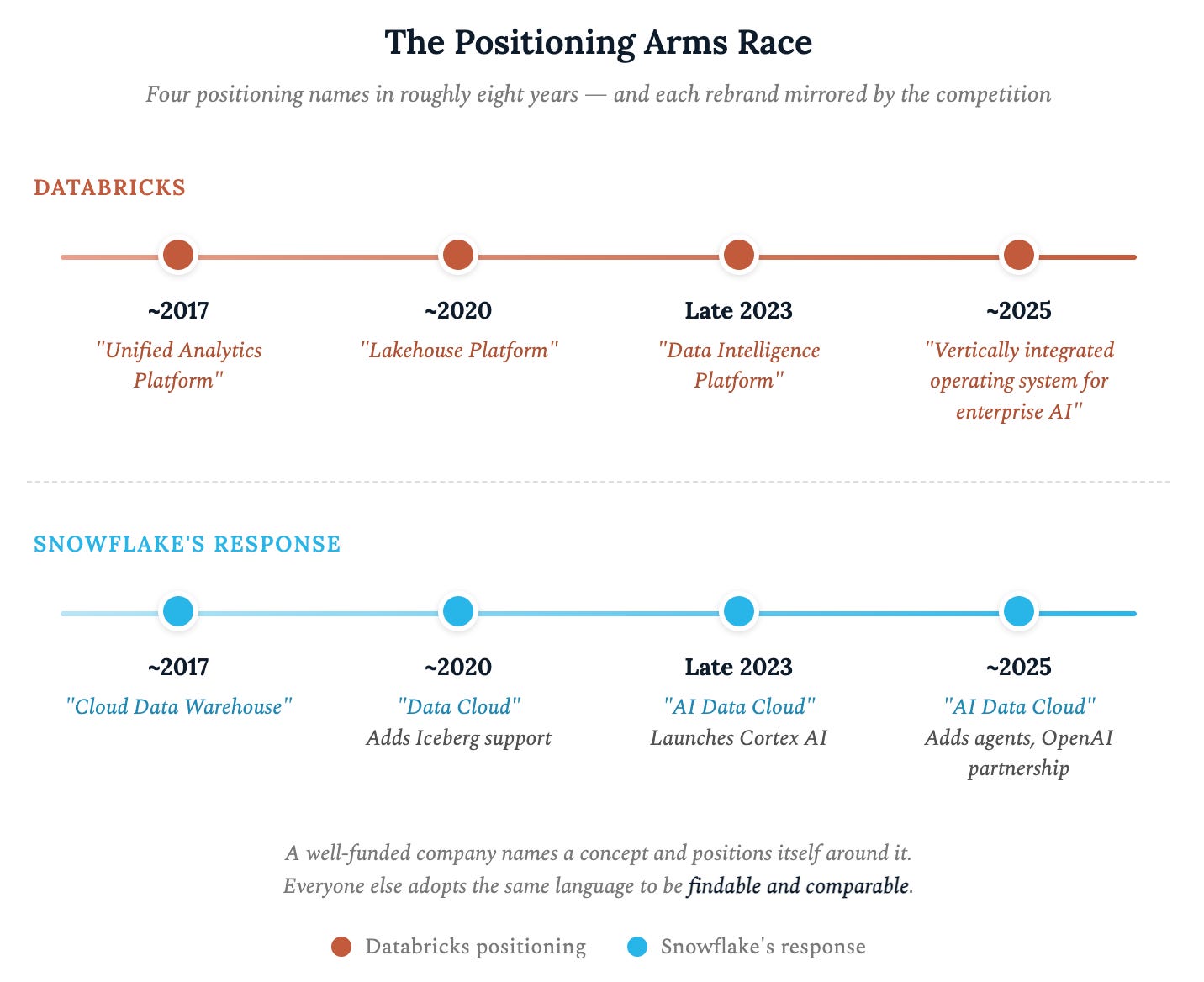
Then there’s “AI-ready data.” The phrase exploded after 2023, now used by IBM, Gartner, Alteryx, Denodo, Dremio, DataHub, Atlan, Informatica, dbt, and more. One company didn’t coin it. Gartner did; with a stat: “63% of organizations lack AI-ready data management practices” and vendors claimed it. It now appears so universally and says nothing about any specific offering.
The vocabulary gets set by two or three leaders. Everyone else optimizes for proximity instead of differentiation.Analyst vocabulary locks everyone in. Gartner and Forrester evaluate markets and create the vocabulary that defines them. Companies optimize messaging to match, because enterprise buyers use analyst terms in RFPs and budget justifications.
Gartner coined “augmented analytics” and “data fabric,” both are now universally adopted. When Gartner published its first Market Guide for Data Observability Tools in 2024, it formalized a category that Monte Carlo says it created in 2019. Every observability vendor immediately aligned their language to Gartner’s definition. The 2025 Gartner Magic Quadrant for Data Integration Tools made “AI-ready data” the central evaluative lens. Within months, that vocabulary appeared on almost every homepage. Informatica leads its homepage with Gartner Magic Quadrant recognition across five separate MQs.
Analyst categories serve as a linguistic constraint. Use different vocabulary from the Gartner category definition and you risk being excluded from the evaluation enterprise buyers rely on. The rational response is conformity. Homepage headlines read like Gartner category definitions because they are.TAM anxiety stops anyone from choosing. The broadness of AI data company messaging is deliberate. It’s a strategic choice to not have a specific buyer, driven by investor expectations and competitive pressure.
No company among the eight audited has a publicly stated Ideal Customer Profile. When Snowflake says “for everyone,” Databricks can’t afford to say “for data engineers only.” Platform economics reward horizontal claims. Sales teams need flexibility to pitch any prospect without marketing materials contradicting them.
These three reasons are mutually inclusive. Category adolescence creates a vocabulary vacuum that leaders fill. Analyst capture formalizes that vocabulary into evaluation criteria. TAM anxiety ensures no company breaks from the pack because the perceived costs of specificity like smaller market, analyst exclusion, sales friction, appear to outweigh the benefits. The system self-perpetuates.
Here’s the thing, though. For Databricks and Snowflake, this status quo is fine. For everyone else, the ones that are still earning their first thousand customers, copying the copy is a strategic error disguised as a safe bet. You end up competing on the incumbent’s terms, with a fraction of their budget.
Two That Broke the Pattern
The selection criterion was only positioning, and two stood out. These had undeniably a more specific positioning. They made the deliberate choice to be narrow and use it as an advantage.
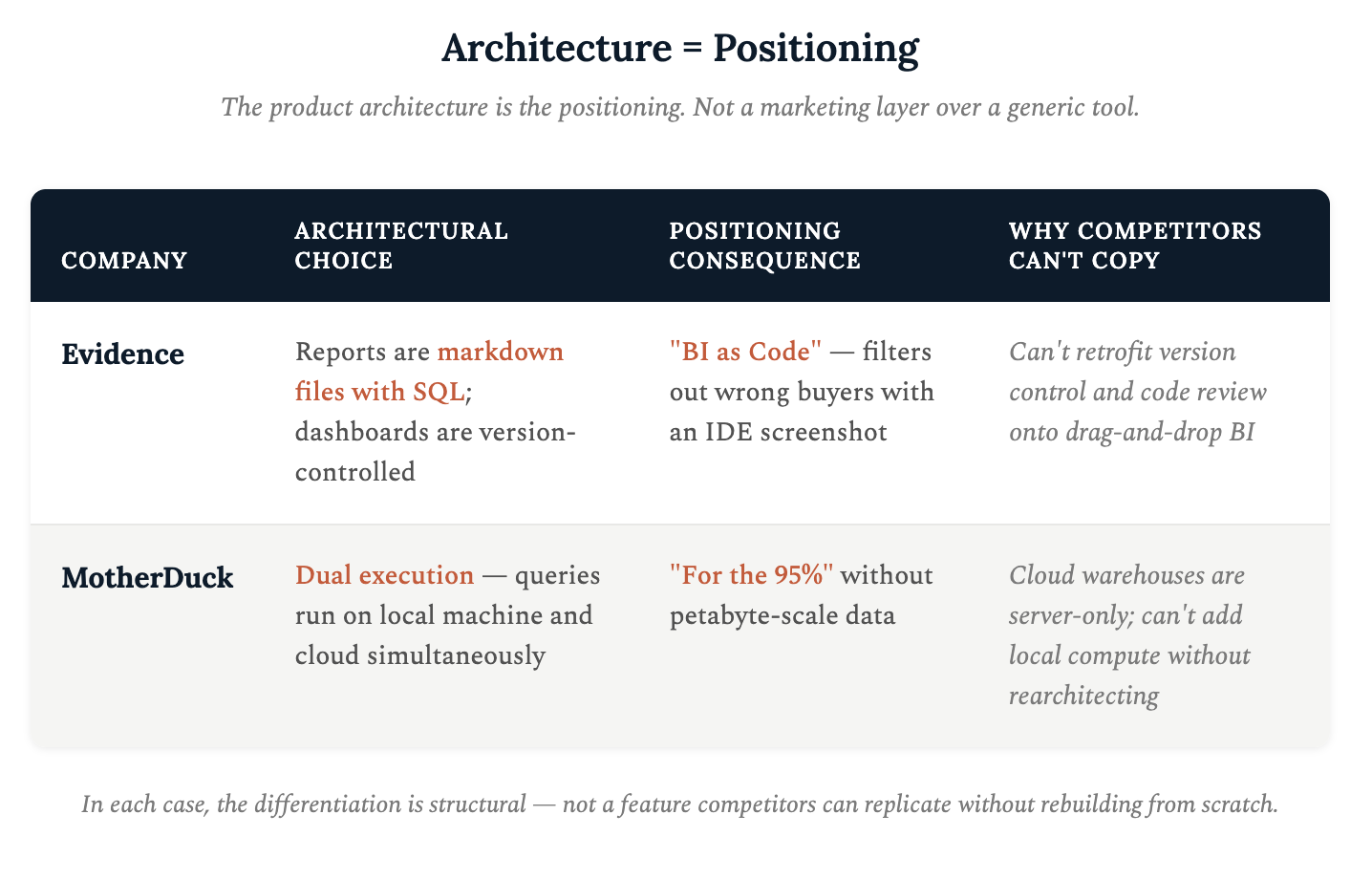
Evidence told most of the market it wasn’t for them. Their tagline is “Business Intelligence as Code.” Reports are markdown files with embedded SQL queries. Dashboards are version-controlled by default. Changes go through PRs (pull requests) before publishing. The homepage shows an IDE screenshot and code syntax instead of a dashboard mockup. A visual way to filter out the wrong buyer before they read a word.
Their buyer definition is so surgical that its documentation states, “To use Evidence you need to know SQL. A knowledge of basic markdown syntax is also helpful.” If you know SQL and markdown, you’re in. If you don’t, this product explicitly isn’t for you.
This is a direct rejection of the dominant BI space. Where Tableau and Power BI use “empower business users,” Evidence uses software engineering vocabulary - version control, testing, deployment etc. The deliberate exclusion is what makes the positioning work so well. Growth signals also confirm it with 5,800+ GitHub stars, 17K+ weekly npm downloads, a 2K+ member Slack community, SOC 2 Type II certification, and transparent pricing at $15–$25/user.MotherDuck named the 95% nobody else acknowledged. CEO Jordan Tigani helped create Google BigQuery and led it through its first ~$1B in revenue. Then he publicly argued that most people don’t need BigQuery.
His thesis gave the most specific buyer definition in the cloud data warehouse market. “For the 95% of us who do not have petabyte-scale data.” It names a situation where you’re overpaying for compute you don’t need and a trigger when you realize your Snowflake bill doesn’t match your data volume. MotherDuck identified its personas based on the problem they’re trying to solve, their jobs-to-be-done.
MotherDuck’s homepage screenshot MotherDuck’s “Dual Execution” model runs queries simultaneously on your local machine and in the cloud. The client is a compute node. This is fundamentally different from every other cloud warehouse where all computation happens server-side.
And, it’s working: ~$133M in total funding at a roughly $496M post-money valuation. Transparent pricing with a free tier at 10GB, paid tiers at $25/month and $100/month with per-second billing. Press coverage consistently uses MotherDuck’s own language. Journalists describe it as “serverless DuckDB in the cloud” and cite the “Big Data is Dead” thesis directly. The positioning has been validated and adopted by the market. It wasn’t forced on it and therefore, it’s more credible.

Two honorable mentions: Dagster published an essay called “The Rise of the Data Platform Engineer” that coined a new buyer identity about the specific person who builds the platform that enables others to build pipelines (quite different than a data engineer). Recce opens with a qualifier question: “You wouldn’t merge untested code. Why merge untested data?” Their self-described category, “data change management,” didn’t exist before they named it. Their ICP is the narrowest in the space: anyone opening a PR that touches dbt models.
The Common Denominator
All four share a trait that separates them from the sameness cohort. Their positioning specificity is a direct consequence of strategic choices that can’t be replicated as features.
So What?
The sameness across AI data companies isn’t a branding problem that better copywriters can fix. It’s an outcome of how enterprise software markets get shaped. Analyst firms define categories. Companies optimize messaging to match. Investors reward broad TAM claims. Sales teams prefer flexibility. Sounding the same makes sense; it feels safer.
The companies that escape this share a counterintuitive insight. They don’t differentiate through fancy words. They differentiate through product constraints that make certain words true only for them.
The next companies to break through won't be the ones that find smarter adjectives. They'll be the ones that make a strategic choice so specific that the positioning writes itself.